


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Asahi, Yuichi*; Latu, G.*; Bigot, J.*; Maeyama, Shinya*; Grandgirard, V.*; Idomura, Yasuhiro
Concurrency and Computation; Practice and Experience, 32(5), p.e5551_1 - e5551_21, 2020/03
Times Cited Count:1 Percentile:14.03(Computer Science, Software Engineering)Two five-dimensional gyrokinetic codes GYSELA and GKV were ported to the modern accelerators, Xeon Phi KNL and Tesla P100 GPU. Serial computing kernels of GYSELA on KNL and GKV on P100 GPU were respectively 1.3x and 7.4x faster than those on a single Skylake processor. Scaling tests of GYSELA and GKV were respectively performed from 16 to 512 KNLs and from 32 to 256 P100 GPUs, and data transpose communications in semi-Lagrangian kernels in GYSELA and in convolution kernels in GKV were found to be main bottlenecks, respectively. In order to mitigate the communication costs, pipeline-based and task-based communication overlapping were implemented in these codes.
Idomura, Yasuhiro; Ina, Takuya*; Mayumi, Akie; Yamada, Susumu; Matsumoto, Kazuya*; Asahi, Yuichi*; Imamura, Toshiyuki*
Proceedings of 8th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2017), p.7_1 - 7_8, 2017/11
A communication-avoiding generalized minimal residual (CA-GMRES) method is applied to the gyrokinetic toroidal five dimensional Eulerian code GT5D, and its performance is compared against the original code with a generalized conjugate residual (GCR) method on the JAEA ICEX (Haswell), the Plasma Simulator (FX100), and the Oakforest-PACS (KNL). The CA-GMRES method has 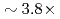 higher arithmetic intensity than the GCR method, and thus, is suitable for future Exa-scale architectures with limited memory and network bandwidths. In the performance evaluation, it is shown that compared with the GCR solver, its computing kernels are accelerated by
higher arithmetic intensity than the GCR method, and thus, is suitable for future Exa-scale architectures with limited memory and network bandwidths. In the performance evaluation, it is shown that compared with the GCR solver, its computing kernels are accelerated by 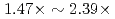 , and the cost of data reduction communication is reduced from
, and the cost of data reduction communication is reduced from 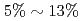 to
to 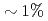 of the total cost at 1,280 nodes.
of the total cost at 1,280 nodes.
Idomura, Yasuhiro
no journal, ,
In performing extreme scale CFD simulations on many core platforms with low power consumption such as Oakforest-PACS, we need new computing technologies for accelerating computation on many core processors, and avoiding communications and data I/O, which become bottlenecks with accelerated computation. In order to resolve these issues, we have developed many core optimization techniques, communication latency hiding techniques, communication avoiding algorithms, and In-Situ visualization systems on Oakforest-PACS. In this talk, we present applications of these techniques to five dimensional plasma CFD codes and three dimensional multi-phase thermal hydraulic CFD codes.
